Скачать бесплатно индикатор Предсказатель на основе самообучающейся нейронной сети от gpwr для MetaTrader 4 в MQL5 Code Base, 2009.06.16
Neural Network Trend Predictor — очень интересный индикатор на основе нейронных сетей
Может есть у кого? Или кто достать может?
И просто выскажите мнение, такое возможно вообще?
alex72
Новичок
Ответ: Neural Network Trend Predictor — очень интересный индикатор на основе нейронн
v1ctys
Интересующийся
Ответ: Neural Network Trend Predictor — очень интересный индикатор на основе нейронн
Ну всё таки если есть что сказать говорите. Думаю многие не знают как следует о нейросетях, в том числе и я.
alex72
Новичок
Ответ: Neural Network Trend Predictor — очень интересный индикатор на основе нейронн
Victys, в двух словах нейросетях не написать. целые книжки написаны по этому поводу. а если в двух словах.
Существуют целые программы для нейросетках, а тут просто индикатор. настораживает. на «вход» как правило подают набор условий включая индикаторы, а вот на выходе (после тренировки сетки) выходят сигналы для торговли. по идее сетка сама «обучается» . как может индюк «обучаться» — загадка. ладно. и второе . нейросетки сейчас «топчутся» на месте. нет «прорыва». по этому пока то, что вы видите в сетях (платное/бесплатное) всё это, мягко говоря «сырой материал». хотя я тоже верю, что за нейросетями будущее. но пока. это в двух словах и очень упрощённо я написал. очень сложная тема — нейросети.
v1ctys
Интересующийся
Ответ: Neural Network Trend Predictor — очень интересный индикатор на основе нейронн
Aisller
Главный модератор
Ответ: Neural Network Trend Predictor — очень интересный индикатор на основе нейронн
К словам alex72 добавлю: что для нейросетей используются очень сильные вычислительные машины, так как алгоритмы сами по себе требуют громадных расчетов ввиду большого кол-ва начальных данных.
Если по индикатору, то сейчас нейросети очень модное слово, поэтому с ним проще впарить индикатор.
Интересующийся
Ответ: Neural Network Trend Predictor — очень интересный индикатор на основе нейронн
Victys, в двух словах нейросетях не написать. целые книжки написаны по этому поводу. а если в двух словах.
Существуют целые программы для нейросетках, а тут просто индикатор. настораживает. на «вход» как правило подают набор условий включая индикаторы, а вот на выходе (после тренировки сетки) выходят сигналы для торговли. по идее сетка сама «обучается» . как может индюк «обучаться» — загадка. ладно. и второе . нейросетки сейчас «топчутся» на месте. нет «прорыва». по этому пока то, что вы видите в сетях (платное/бесплатное) всё это, мягко говоря «сырой материал». хотя я тоже верю, что за нейросетями будущее. но пока. это в двух словах и очень упрощённо я написал. очень сложная тема — нейросети.
Ничего тут не настораживает. Сказываются ваши знания в области ИИ. Нейросети это метод. О каком прорыве вы говорите. Это всё равно что говорить нет прорыва в линейной регрессии.
Зарегистрируйтесь на том сайте и посмотрите в разделе downloads кто и как использует нейросети.
Касательно этого индикатора, то сеть там уже обучена, и не дообучаеться. Задача той нейросети найходить закономерности в ценовых паттернах и показывать вероятностную картину. Помимо нейросети там есть ещё один метод прогнозирования. Вообще отличный от нейросетей, и тоже экстраполяция.
добавлено через 6 минут
К словам alex72 добавлю: что для нейросетей используются очень сильные вычислительные машины, так как алгоритмы сами по себе требуют громадных расчетов ввиду большого кол-ва начальных данных.
Если по индикатору, то сейчас нейросети очень модное слово, поэтому с ним проще впарить индикатор.
Всё зависит от задачи. Классический пример нейросетей приводится на примере операции XOR. Очень сильные вычислительные машины тут не нужны. И начальных данных 8 цифр.
Всё зависит от задачи. Хотя вы правы, с количеством нейронов в нейросети обьём вычислений растёт экспотенциально (и это зависит от архитектуры сети). И опять таки всё зависит от поставленной задачи.
Нейросети были модны в 60х. На данном этапе существует туча алгоритмов для классификации и аппроксимации. А модно сейчас думаю Fuzzy Neural Tree. уффф.
Предсказатель на основе самообучающейся нейронной сети — индикатор для MetaTrader 4
Для авторизации и пользования сайтом MQL5.com необходимо разрешить использование файлов Сookie.
Пожалуйста, включите в вашем браузере данную настройку, иначе вы не сможете авторизоваться.
Автор:
История версий:
16/06/2009 — в индикаторы BPNN Predictor.mq4 и Buy-Sell Classificator.mq4 добавлены проверки на появление нового бара чтобы тиковое обновление on-line графиков не перезапускало вычисления. Добавлен новый BPNN.zip файл содержащий недостающие системные DLL файлы.
17/06/2009 — добавлена проверка на скорость уменьшения ошибки в BPNN.cpp существенно увиличивающаяся скорость вычислений. Приложены новые файлы BPNN.zip и BPNN.dll.
- файл BPNN.dll скомпилирован таким образом что он теперь включает все необходимые системные функции
- добавлены две новые функции активации нейронов: tanh и рациональная
- удалена проверка на скорость уменьшения ошибки в BPNN.cpp
- встроен новый, более надёжный алгоритм обучения iRProp+
- Старые файлы индикаторов не будут работать с новым BPNN.dll
- удалён Buy-Sell Classificator.mq4 так как он пока не работает. Он может появиться снова здесь как только я доведу его до ума.
— добавлен новый индикатор BPNN Predictor with Smoothing.mq, который до предсказания цен сглаживает их скользящей средней
20/08/2009 — исправлен код вычисления функции активации нейрона чтобы предотвратить зашкаливание. Обновлены файлы BPNN.dll и BPNN.cpp.
21/08/2009 — добавлена очистка памяти. Обновлены файлы BPNN.dll и BPNN.cpp.
Предлагается индикатор использующий нейронную сеть прямого распространения (feedforward neural network), которая самообучается методом Обратного Распространения Ошибки (backpropagation). Сеть загружается через DLL файл, исходный C++ код которого прилагается.
Нейронная сеть это ничто иное как нелинейная модель выходов как функция входов. На входы подаются данные задаваемые пользователем, например выборки временного ряда. Смысл выходных данных также задаётся пользователем, например сигналы 1=buy/0=sell. Структура сети опять же задаётся пользователем. Сеть прямого распространения состоит из
—входного слоя (input layer), элементами которого являются входные данные,
— скрытых слоёв (hidden layers), состоящих из вычислительных узлов называемых нейронами (neurons) и
— выходного слоя (output layer), который состоит из одного или нескольких нейронов, выходы которых являются выходами всей сети.
Все узлы соседних слоёв связаны между собой. Эти связи называются синапсами (synapses). Каждый синапс имеет вес (weight w[i,j,k]), на которой умножаются данные передаваемые по синапсу. Данные передвигается слева направа т.е. от входов сети к её выходам. Отсюда и название, «сеть прямого распространения». Общий пример этой сети изображён на рисунке внизу
Данные перерабатываются нейронами за два шага:
1. Все входы, помноженные на соответствующие веса, сначала суммируются
2. Затем получившиеся суммы обрабатываются функцией активации нейрона (activation or firing function) и посылаются на единственный выход.
Смысл функции активации нейрона заключается в моделировании работы нейрона мозга: нейрон срабатывает только после того как информация достигла определённого порога. В математическом аспекте, эта функция как раз и придаёт нелинейность сети. Без неё, нейронная сеть была бы линейной авторегрессионной моделью (linear prediction model). В прилагаемых библиотечных функциях возможен выбор трёх функций активации нейрона
- сигмоидальная функция sigm(x)=1/(1+exp(-x)) (#0)
- гиперболический тангенс tanh(x)=(1-exp(-2x))/(1+exp(-2x)) (#1)
- рациональная функция x/(1+|x|) (#2)
Порог активации этих функций равен 0. Этот порог может быть сдвинут по горизонтальной оси за счёт дополнительного входа нейрона называемом входом смещения (bias input), которому приписан определённый вес таким же образом как и к другим входам нейрона.
Таким образом, количество входов, слоев, нейронов в каждом слою и веса входов нейронов полностью определяют нейронную сеть, т.е. нелинейную модель, которую она создаёт. Чтобы пользоваться этой моделью необходимо знать веса. Веса вычисляются путём обучения сети на прошлых данных: на входы сети подаются нескольков наборов входных и соответствующих выходных данных и рассчитывается среднеквадратичная ошибка отклонения выхода сети от тестируемого. Цель обучения сети заключается в уменьшении этой ошибки путём оптимизации весов. Существуют несколько методов оптимизации, среди которых основными эвляются метод Обратного Распространения Ошибки (ОРО) и метод генетической оптимизации. Метод ОРО является пу существу методом градиентного спуска и вкратце опиан здесь
В прилагаемой функции Train() используется разновидонсть метода ОРО называемая «Улучшенный Эластичный метод ОРО» (Improved Resilient back-Propagation, IRProp). Этот алгоритм описан здесь
Прилагаемые файлы:
- BPNN.dll — библиотечный файл
- BPNN.zip — архив всех файлов необходимых для создания ДЛЛ файла
- BPNN Predictor.mq4 — индикатор предсказывающий будущее значение цены
- BPNN Predictor with Smoothing.mq4 — индикатор предсказывающий будущее значение цены, сглаженной ЕМА
Библиотечный файл BPNN.cpp содержит две функции: Train() и Test(). Train() предназначен для обучения сети для предоставленных входных и выходных данных. Test() предназначен для вычисления выходных данных на основе весов полученных после прогона Train().
Входными (зелёный цвет) и выходными (синий цвет) параметрами функции Train() являются:
double inpTrain[] — обучивающие входные данные (старый первый)
double outTarget[] — обучивающие выходные данные (старый первый)
double outTrain[] — выходы сети после обучения
int ntr — количество обучающих наборов входы-выходы
int UEW — ключ управляющий использованием внешних значений для инициализации весов (1=используем extInitWt[], 0=используем случайные числа)
double extInitWt[] — исходные значения весов
double trainedWt[] — значения весов после обучения
int numLayers — количество слоев в сети включая входной, скрытые и выходной
int lSz[] — одомерный массив размера numLayers, в котором хранятся количества нейронов в каждом слою. lSz[0] задаёт количество входов сети
int AFT — тип функции активации (0-сигмоидальная, 1-гиперболический тангенс, 2-рациональная)
int OAF — ключ использования функции активации в выходны нейронах (1=используем функцию активации, 0=нет)
int nep — максимальное количество обучающих шагов (эпох). Эпоха состоит из проверки всех обучающих наборов.
double maxMSE — среднеквадратичная ошибка, при которой обучения останавливается.
Входными (зелёный цвет) и выходными (синий цвет) параметрами функции Test() являются:
double inpTest[] — входные данные (старый первый)
double outTest[] — выходные данные
int ntt — колчиство наборов в входных и выходных данных
double extInitWt[] — исходные значения весов
int numLayers — количество слоев в сети включая входной, скрытые и выходной
int lSz[] — одомерный массив размера numLayers, в котором хранятся количества нейронов в каждом слою. lSz[0] задаёт количество входов сети
int AFT — тип функции активации (0-сигмоидальная, 1-гиперболический тангенс, 2-рациональная)
int OAF — ключ использования функции активации в выходны нейронах (1=используем функцию активации, 0=нет)
Использование функции активации в выходных нейронах зависит от характера выходны данных. Если выходами сети являются биноминальные сигналы (0/1 или -1/1), то нужно использовать функцию активации (OAF=1). Причём учтите что для функции №0, уровни сигнала 0 и 1, а для функций №1 и 2 уровни -1 и 1. Если выходом сети является предсказание цены, то функция активации в выходном слое не нужна (OAF=0).
Примеры индикаторов использующих нейронную сеть:
BPNN Predictor.mq4 — предсказывает будущие цены. Входными параметрами сети являются относительные приращения цен:
где delay[i] берётся из ряда Фибоначи. Выходом сети является предсказываемое относительное приращение будущей цены. Фунцкия активации в выходном слое отключена.
Входными параметрами индикатора являются
extern int lastBar — номер последнего бара
extern int futBars — количество будущих предсказываемых баров
extern int numLayers — количество слоев в сети включая входной, скрытые и выходной
extern int numInputs — количество входов сети
extern int numNeurons1 — количество нейронов в слое №1
extern int numNeurons2 — количество нейронов в слое №2
extern int numNeurons3
extern int numNeurons4
extern int numNeurons5
extern int ntr — количество обучающих наборов входы-выходы
extern int nep — максимальное количество обучающих шагов (эпох)
extern int maxMSEpwr — экспонента используемая для расчёта максимальной допустимой среднеквадратической ошибки обучения maxMSE=10^maxMSEpwr
extern int AFT — тип функции активации (0-сигмоидальная, 1-гиперболический тангенс, 2-рациональная)
Индикатор выдаёт такую картинку, где
- красный цвет — предсказания от последней цены Open
- чёрный цвет — прошлые тренировочные цены Open, по котором (как ожидаемым выходным данным) проводилось обучение сети
- синий цвет — выходы обученной сети на тренировочных данных
BPNN Predictor with Smoothing.mq4 — тоже предсказывает цены, но с предварительным сглаживанием цен экспоненциальной скользящей средней (EMA) с периодом smoothPer.
Установка файлов:
- Копируйте приложенный BPNN.DLL файл в C:Program FilesMetaTrader 4expertslibraries
- Включайте использование DLL в метатрейдере: Tools — Options — Expert Advisors — Allow DLL imports
Если приложенный DLL файл не работает, то компилируйте сами. Все необходимые файлы содержатся в BPNN.zip.
Советы:
- Сеть с 3-ми слоями (numLayers=3: один входной, один скрытый и один выходной) достаточна для подавляющего большинства применений. По теоремe Cybenko (1989) сеть с одним скрытым слоем может моделировать любую непрерывную нелинейную фунцкию и сеть с двумя скрытыми слоями способна описать функцию с разрывами (http://en.wikipedia.org/wiki/Cybenko_theorem):
- Количество нейронов в скрытом слую определяйте экспериментально. В литературе встречаются такие рекомендации: кол-во скрытых нейронов = (кол-во входов + кол-во выходов)/2, либо SQRT(кол-во входов * кол-во выходов). Следите за сообщениями о среднеквадратичной ошибки обучения в окне experts метатрейдера.
- Для получения хорошего обобщения, количество обучающих выборок должно в 2-3 раза превышать количество оптимизируемых весов. Например, в опубликованных примерах, количество весов равно (12+1)*5 на входах скрытого слоя плюс (5+1) на входах выходоного слоя, т.е. 71. Поэтому количество обучающих выборок должно быть по крайней мере 142. Концепт обобщения объяснён на рисунке внизу для одномерного случая y(x).
- Увеличения количества обучающих эпох может не повысить точность предсказаний на тестируемых данных даже если ошибка обучения (MSE) уменьшилась. При большом количестве весов сеть становится переученной (см объяснения внизу).
- Входные данные должны преобразоваться в стационарный ряд. Цены сами по себе таковым рядом не являются. Рекомендуется также нормализовывать входные данные к диапазону -1..1.
На этом графике показана линейная функция y=b*x (x-вход, y-выход) с добавленным шумом к выходам. Из-за этого шума, измерения функции (чёрные точки) не лежат на прямой. Функция y=f(x) может быть смоделирована нейронной сетью. Сеть с большим количеством весов (степеней свободы) способна уменьшить ошибку обучения по всем имеюшимся измерениям до нуля и описать тренировочные выходные данные плавной кривой. Но эта кривая (показана красным цветом) не имеет ничего общего с нашей линейной фунцкией y=b*x (показана зелёным цветом). Использование такой сети для предсказания будущих значений функции y при новых входных значениях x приведёт к большим ошибкам так как шум не предсказуем.
Уважительная Просьба: eсли вам удастся создать прибыльный советник на основе этих файлов, пожалуйста поделитесь идеей в личку или vlad1004@yahoo.com.
О тех индикаторах с точки зрения нейросетей.

Что если в качестве лейблов на выход подавать не рост/падение рынка завтра, а срабатывание каких то техиндикаторов? Есть несколько классических правил торговли. Ну например пробой снизу вверх Close BolingerUpperband это к покупке, и сверху вниз BolingerDownperband к шорту. Или дивергенция MACD. Или Close пробивает SMA. Ну а че вы смеетесь? Когда я работал в представительстве Финама, мы предлагали клиентам следовать корпоративной стратегии, а вся стратегия это пробои Болинджеров. Я, как человек который вообще тогда не понимал как это все делается, готовился услышать какую то хитрую систему для зарабатывания денег, от московских экспертов, а когда услышал «тайну», я такой «эээээ. ». Или вот дивергенция MACD, открываешь википедию и там прямо «это сильнейший технический индикатор, если дивергенция то вот прям точно точно!».
Месяц назад я пробовал подать на вход CNN+GramianAngular падение/рост рынка, без каких то видимых успехов. Может тут проблема в инструменте? Попробуем спрогнозировать с помощью нейросети срабатывание этих самых техиндикаторов, подав цены накануне. Причем усложним задачу, будем подавать не точное число баров, а фиксированное, скажем 30. То есть нейросетка получает избыточные данные: мы хотим предсказать пересечение Close c SMA(25) а мы ей 30 баров предлагаем.
Сразу скажу, что результаты хорошие. Особо я не утруждался долгим обучением, но видно как сетка очень шустро, от эпохи к эпохе улучшает показатели точности. Ине суть что мы предсказываем — Bolinger, MACD, SMA, результаты примерно одинаковы, или их можно сделать одинаковыми обучив нейросеть чуть подольше. И на test выборке все хуже не становится.
Архитектура такая:
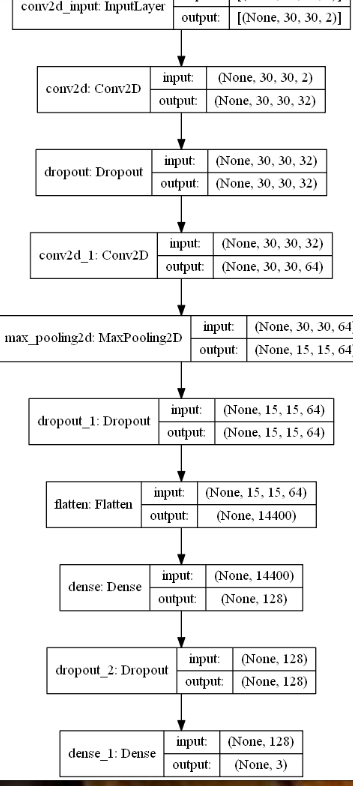
Угадывает она срабатывание тех индикаторов с точностью на test 85-90%.
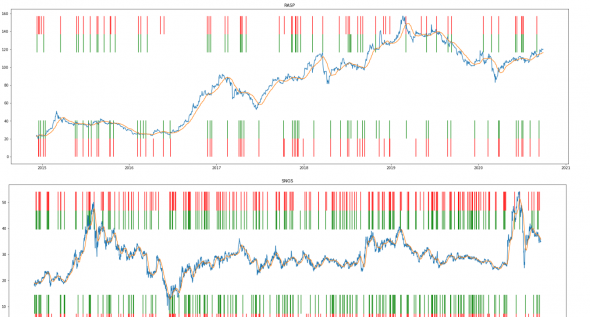
Для любителей усваивать информацию зрительно, взял котировку какой то фишки, наложил на нее SMA25 и красными стрелками указал пересечение ее Close. Красные черточки сверху это пересечение сверху вниз, нижние-наоборот. Ну а зеленые это прогнозы. Как видим угадываем с высокой точностью.
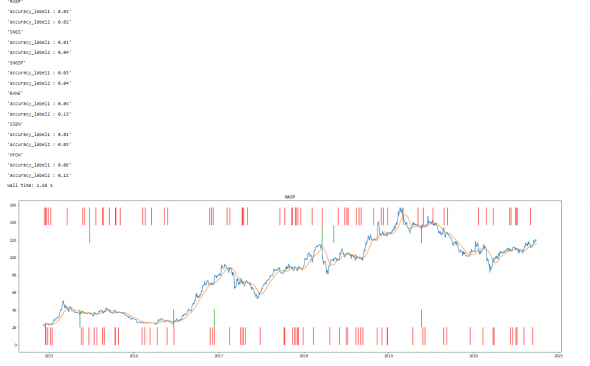
Ну и некоторые циферки

Если сеть не путать и подавать точно число баров, то сеть начинает чуть быстрей обучаться, а так разницы нет, что позитивненько. Приятная инвариантность. И для смеха я сделал наоборот, дал сети недостаточное число данных (10 баров для пересечения с SMA(25)) — выкручивайся мол. Опять не стал долго обучаться, 10 минут и будя. Тем более что обучение застряла на определенной отметке, без какого то улучшения (что логично, как говорится иди незнаю куда, принеси то незнамо что-это трудно). Ну и на прогнозе чуда не произошло
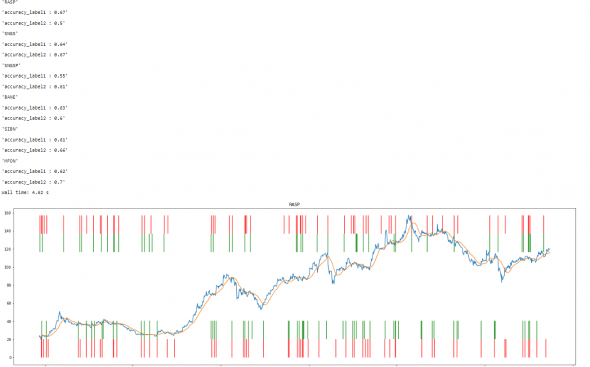
Если вместо 25 необходимых подать 20 баров, то результаты будет получше:
Ну и если кто то дочитал до этого момента, вполне возможно задастся вопросом, что то типа «а зачем вообще все это нужно?!». Где профит?! Мани где?! Нет тут профитов и нет мани, мы ответили на вопрос-может ли CNN получив на выход сырой ряд ряд цен, спрогнозировать срабатывание тех индикаторов. То есть по сути, может ли CNN улавливать сложные конфигурации time series. Ответ — да, может. Ура товарищи. Вот вы можете по одному виду временного рядка сказать будет на следующем баре дивергенция MACD, или пересечение Bolinger или SMA? А моя нейросеть может.
Хотя одно практическое применение я могу придумать-ну вот например вы нашли какое то чудесное сочетание тех индикаторов, которые приносят профит. И хотите это показать публике. Но засвечивать Грааль не хотите. Ну так проставьте лейблы, и обучаете нейросеть по ним, и вот можете совать свою систему в продакшн, она еще и выглядеть будет круче, ибо «торговая система на основе нейросеть» звучит в наше время интересно, а кому нужна система на техниндикаторах?!
Для справедливости сеть все таки получила не сырой ряд данных, а предобработанный, будет интересно глянуть на сеть, если подать ей именно сырой. 1CNN. Вот этим я и займусь дальше.
А практический вывод из всего этого я вынес что надо поработать с lebeling.
Таки дела.
Источник https://mmgp.com/threads/neural-network-trend-predictor-ochen-interesnyj-indikator-na-osnove-nejronnyx-setej.38358/
Источник https://www.mql5.com/ru/code/8976
Источник https://smart-lab.ru/blog/651217.php
